Ever had a perfectly good JavaScript application suddenly break in production with a cryptic error message you never saw during development? We’ve all been there. The dynamic nature of JavaScript, while flexible, can sometimes lead to unexpected issues that only surface when your code is actually running. This is where TypeScript comes to the rescue.
Think of TypeScript not as a completely new language, but as a helpful layer on top of JavaScript. It’s what’s called a “superset,” meaning all valid JavaScript code is also valid TypeScript code. The magic happens when you add “types” to your code. These types act like labels or descriptions for the kind of data your variables, function parameters, and function returns are expected to hold.
Why is this so powerful, especially for beginners? Because TypeScript introduces something called “static typing.” Unlike JavaScript, which checks for errors while your code is running (runtime), TypeScript checks for potential errors before you even run it (static analysis). This means many common mistakes – like trying to perform a mathematical operation on a string, or calling a method on an object that doesn’t exist – can be caught right in your code editor, saving you valuable debugging time down the line.
Getting Started: Your First Steps
Ready to see this in action? Learning TypeScript from scratch is more accessible than you might think. You’ll need Node.js and a package manager like npm or yarn installed on your computer. If you have those, open your terminal and type:
npm install -g typescript
This command installs the TypeScript compiler globally on your system. The compiler, tsc, is the tool that takes your TypeScript code (.ts files) and converts it into plain JavaScript code (.js files) that browsers and Node.js can understand.
Let’s create a simple example. Make a file named greeter.ts and add this code:
TypeScript
function greeter(person: string) {
return "Hello, " + person;
}
let user = “World”;
console.log(greeter(user));
Here, : string is a type annotation. We’re telling TypeScript that the person parameter in the greeter function is expected to be a string. Now, if you try to call greeter(5) instead of greeter(“World”), your code editor (if it has TypeScript support, like VS Code) will immediately flag it as an error before you run it. This instant feedback loop is incredibly valuable.
To compile this TypeScript file into JavaScript, open your terminal in the same directory and run:
tsc greeter.ts
This will create a greeter.js file:
JavaScript
function greeter(person) {
return "Hello, " + person;
}
var user = “World”;
console.log(greeter(user));
Notice how the type annotation : string is gone in the generated JavaScript. TypeScript types are only used during the development and compilation phase; they don’t add any overhead to your runtime code.
Beyond the Basics: Core Concepts
As you continue your [typescript tutorial](link urlhttps://www.tpointtech.com/typescript-tutorial) journey, you’ll encounter fundamental concepts that form the backbone of the language:
Type Inference: Often, TypeScript can figure out the type of a variable based on the value you assign it, so you don’t always need explicit type annotations. For example, let age = 30; will automatically infer age as a number.
Interfaces: These allow you to define the structure or “shape” of objects. This is immensely helpful when dealing with complex data structures, ensuring that objects have the properties you expect with the correct types.
Union Types: Sometimes a variable might hold one of several types. Union types (string | number) let you express this possibility clearly.
Arrays: You can specify the type of elements an array will contain, like let numbers: number[] = [1, 2, 3];.
Why Bother with Types?
Adding types might seem like extra work at first, but the benefits quickly become apparent:
Catch Errors Early: As mentioned, this is the biggest win. Fewer runtime errors mean more stable applications and less time spent debugging.
Improved Code Readability: Types act as documentation. Looking at a function signature (user: { name: string, age: number }): string immediately tells you what kind of object it expects and what it will return.
Enhanced Tooling: Editors with TypeScript support offer amazing autocompletion, code navigation, and refactoring capabilities because they understand the structure and types of your code.
Easier Collaboration: When working in a team, types provide a clear contract for how different parts of the code should interact.
Learning TypeScript from scratch is an investment that pays off significantly as your projects grow in size and complexity. It fosters better coding practices and gives you more confidence in the code you write. Ready to dive deeper and explore more concepts? Finding a good [typescript tutorial](link urhttps://www.tpointtech.com/typescript-tutoriall) and starting to apply types to your own small projects is your next step! Happy coding!
 image url)
image url)

 ) serve as the fundamental organizers of our digital files, DBMS offers a more robust, scalable, and feature-rich solution for managing complex and interconnected datasets. Choosing between the two depends entirely on the specific needs of the application. For personal use and simple data organization, a file system is often sufficient. However, for applications dealing with large, shared, and critical data, a DBMS is the indispensable choice. It brings structure, efficiency, reliability, and security to the world of data management, empowering us to handle information in ways a simple filing cabinet never could.
) serve as the fundamental organizers of our digital files, DBMS offers a more robust, scalable, and feature-rich solution for managing complex and interconnected datasets. Choosing between the two depends entirely on the specific needs of the application. For personal use and simple data organization, a file system is often sufficient. However, for applications dealing with large, shared, and critical data, a DBMS is the indispensable choice. It brings structure, efficiency, reliability, and security to the world of data management, empowering us to handle information in ways a simple filing cabinet never could.
 ) describes a software system designed to manage, store, retrieve, and organize data efficiently and securely. Think of it as a digital filing cabinet, but one with advanced capabilities for structuring information, preventing errors, controlling access, and enabling powerful analysis. Unlike simple file systems where data is often scattered and difficult to manage consistently, a DBMS provides a structured environment for data storage and manipulation.
) describes a software system designed to manage, store, retrieve, and organize data efficiently and securely. Think of it as a digital filing cabinet, but one with advanced capabilities for structuring information, preventing errors, controlling access, and enabling powerful analysis. Unlike simple file systems where data is often scattered and difficult to manage consistently, a DBMS provides a structured environment for data storage and manipulation. ) of DBMS in the context of specific organizational needs and resources. While the benefits of improved data consistency, security, integration, and analytical capabilities are undeniable, the costs, complexity, and potential for dependency must also be carefully considered. By understanding both the strengths and weaknesses, organizations can leverage the power of DBMS effectively to navigate the ever-expanding landscape of data.
) of DBMS in the context of specific organizational needs and resources. While the benefits of improved data consistency, security, integration, and analytical capabilities are undeniable, the costs, complexity, and potential for dependency must also be carefully considered. By understanding both the strengths and weaknesses, organizations can leverage the power of DBMS effectively to navigate the ever-expanding landscape of data. ) is the process of hiding the intricate details of data storage and retrieval while providing users with a conceptual view of the data that is easy to understand and work with. Imagine trying to find a specific book in a massive library where the books are scattered randomly without any organization. It would be a chaotic and inefficient process. Data abstraction provides the organizational structure, allowing you to access the information you need without knowing the exact shelf and position of the book.
) is the process of hiding the intricate details of data storage and retrieval while providing users with a conceptual view of the data that is easy to understand and work with. Imagine trying to find a specific book in a massive library where the books are scattered randomly without any organization. It would be a chaotic and inefficient process. Data abstraction provides the organizational structure, allowing you to access the information you need without knowing the exact shelf and position of the book. ) come into play. They act as the silent guardians, ensuring that the data stored within your database adheres to predefined rules and limitations.
) come into play. They act as the silent guardians, ensuring that the data stored within your database adheres to predefined rules and limitations. ) is an attribute or a set of attributes within a table that uniquely identifies each record (tuple) in that table. Think of it as the official ID card for every entry. Just like your social security number uniquely identifies you, the primary key in DBMS ensures that no two rows in a table are exactly the same.
) is an attribute or a set of attributes within a table that uniquely identifies each record (tuple) in that table. Think of it as the official ID card for every entry. Just like your social security number uniquely identifies you, the primary key in DBMS ensures that no two rows in a table are exactly the same. ) is fundamental to grasping the principles of database design and management. They are the building blocks that allow us to model real-world entities and their characteristics in a structured and meaningful way. By carefully defining and categorizing attributes in DBMS, we lay the foundation for efficient data storage, retrieval, and manipulation, ultimately unlocking the power of the information we manage. So, the next time you interact with a database, remember the crucial role these seemingly simple columns play in organizing and making sense of the digital world around us.
) is fundamental to grasping the principles of database design and management. They are the building blocks that allow us to model real-world entities and their characteristics in a structured and meaningful way. By carefully defining and categorizing attributes in DBMS, we lay the foundation for efficient data storage, retrieval, and manipulation, ultimately unlocking the power of the information we manage. So, the next time you interact with a database, remember the crucial role these seemingly simple columns play in organizing and making sense of the digital world around us. ) is a foundational concept in relational database design. It represents a potential unique identifier for records within a table, characterized by uniqueness and minimality. By understanding and identifying candidate keys, database professionals can make informed decisions about primary key selection, ultimately ensuring data integrity, efficient data retrieval, and well-structured database systems. So, the next time you’re designing a database, remember the crucial role of the candidate key in DBMS in unlocking the uniqueness of your data.
) is a foundational concept in relational database design. It represents a potential unique identifier for records within a table, characterized by uniqueness and minimality. By understanding and identifying candidate keys, database professionals can make informed decisions about primary key selection, ultimately ensuring data integrity, efficient data retrieval, and well-structured database systems. So, the next time you’re designing a database, remember the crucial role of the candidate key in DBMS in unlocking the uniqueness of your data.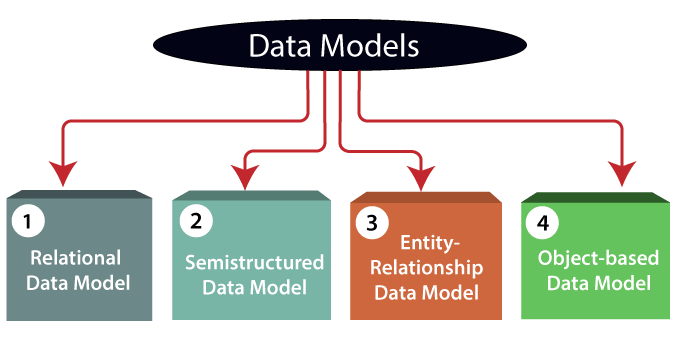 image url))) in DBMS and their respective advantages and disadvantages is essential for anyone involved in designing, developing, or managing databases. By carefully selecting and implementing the appropriate data model in DBMS, organizations can effectively harness the power of their data, turning raw information into valuable insights and driving better decision-making.
image url))) in DBMS and their respective advantages and disadvantages is essential for anyone involved in designing, developing, or managing databases. By carefully selecting and implementing the appropriate data model in DBMS, organizations can effectively harness the power of their data, turning raw information into valuable insights and driving better decision-making.